Here's a quick rundown of how I created the character thought bubbles in this scene using world space canvases.
Creating world space canvases
Canvases are the root object for all Unity GUI elements. By default they render to screen space but you also have the option of rendering the canvas in world space, which is exactly what you need for the Rift. To create a canvas, from the Hierarchy menu, select Create > UI > Canvas. When you create a canvas, both a Canvas object and an Event System object are added to your project. All UI elements need to be added as children of a Canvas. Each thought bubble consist of world-space Canvas, and two UI elements - an image and a text box. For organization, I put the UI elements in an empty gameObject called ThoughtBubble.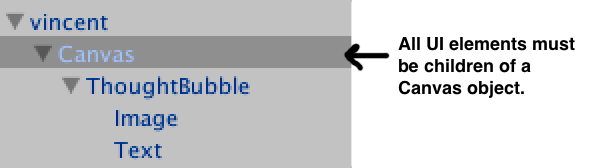
Note. Hierarchy order is important as UI objects are rendered in the order that they appear in the hierarchy.
To have the canvas render as part of the 3d scene, in the Inspector for the Canvas, set the Render Mode to World Space.
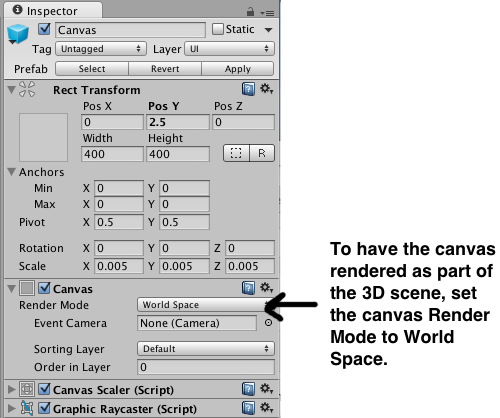
When you change the render mode to world space, you’ll note that the Rect Transform for the canvas becomes editable. Screen space canvases default to the size of the screen, however, for world space canvases you need to set the size manually to something appropriate to the scene.
Setting canvas position, size, and resolution
By default the canvas is huge. If you look in the Inspector, you'll see that it has Width and Height properties as well as Scale properties. The height and width properties are used to control the resolution of the GUI. (In this scene the Width and Height are set to 400 x 400. The thought bubble image is a 200 X 200 px image and the font used for the Text is 24pt Ariel.) To change the size of the canvas you need to set the Scale properties.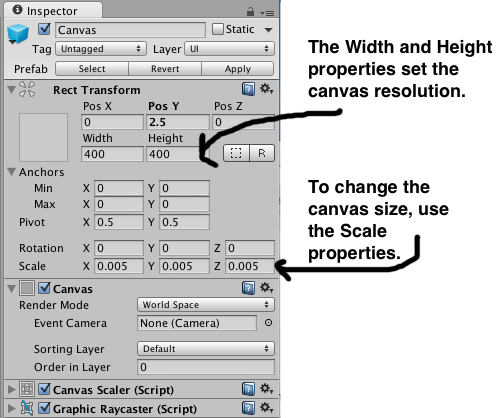
To give you an idea of the proportions, the characters in the scene are all just under 2 units high. and the scale of each canvas is set to 0.005 in all directions. With the canvas a reasonable size, I positioned each canvas just above the character.
Rotating the canvas with the player's view
For the thought bubble to be read from any direction, I attached a script to the Canvas to set the canvas transform to look at the player .using UnityEngine;
using System.Collections;
public class lookatplayer : MonoBehaviour {
public Transform target;
void Update() {
transform.LookAt(target);
}
}
Toggling canvas visibility
When you look at a character the thought bubble appears. The thought bubble remains visible until the you look at another character. There were two ways I looked at for toggling the menu visibility - setting the active state of the UI container gameObject (ThoughtBubble) or adding a Canvas Group component to the UI container gameObject and setting the Canvas Group's alpha property. Changing the alpha property seemed easier as I would not need to keep track of inactive gameObjects, so I went with that method. There is a canvas attached to each character in the scene. The script below is attached to the CenterEyeObject (part of the OVRCameraRig prefab in the Oculus Integration package v. 0.4.4). It uses ray casting to detect which person the user is looking at and then changes the alpha value of the character's attached GUI canvas to toggle the canvas visibility.
using UnityEngine;
using System.Collections;
public class lookatthoughts : MonoBehaviour {
private GameObject displayedObject = null;
private GameObject lookedatObject = null;
// Use raycasting to see if a person is being looked
using System.Collections;
public class lookatthoughts : MonoBehaviour {
private GameObject displayedObject = null;
private GameObject lookedatObject = null;
// Use raycasting to see if a person is being looked
// at and if so, display the person's attached gui canvas
void Update () {
Ray ray = new Ray(transform.position, transform.forward);
RaycastHit hit;
if(Physics.Raycast(ray, out hit, 100)) {
if (hit.collider.gameObject.tag == "person"){
lookedatObject = hit.collider.gameObject;
if (displayedObject == null){
displayedObject = lookedatObject;
changeMenuDisplay(displayedObject, 1);
}else if (displayedObject == lookedatObject){
//do nothing
}else{
changeMenuDisplay(displayedObject, 0);
displayedObject = lookedatObject;
changeMenuDisplay(displayedObject, 1);
}
}
}
}
// Toggle the menu display by setting the alpha value
void Update () {
Ray ray = new Ray(transform.position, transform.forward);
RaycastHit hit;
if(Physics.Raycast(ray, out hit, 100)) {
if (hit.collider.gameObject.tag == "person"){
lookedatObject = hit.collider.gameObject;
if (displayedObject == null){
displayedObject = lookedatObject;
changeMenuDisplay(displayedObject, 1);
}else if (displayedObject == lookedatObject){
//do nothing
}else{
changeMenuDisplay(displayedObject, 0);
displayedObject = lookedatObject;
changeMenuDisplay(displayedObject, 1);
}
}
}
}
// Toggle the menu display by setting the alpha value
// of the canvas group
void changeMenuDisplay(GameObject menu, float alphavalue){
Transform tempcanvas = FindTransform(menu.transform, "ThoughtBubble");
if (tempcanvas != null){
CanvasGroup[] cg;
cg = tempcanvas.gameObject.GetComponents<CanvasGroup>();
if (cg != null){
foreach (CanvasGroup cgs in cg) {
cgs.alpha = alphavalue;
}
}
}
}
// Find a child transform by name
public static Transform FindTransform(Transform parent, string name)
{
if (parent.name.Equals(name)) return parent;
foreach (Transform child in parent)
{
Transform result = FindTransform(child, name);
if (result != null) return result;
}
return null;
}
}
void changeMenuDisplay(GameObject menu, float alphavalue){
Transform tempcanvas = FindTransform(menu.transform, "ThoughtBubble");
if (tempcanvas != null){
CanvasGroup[] cg;
cg = tempcanvas.gameObject.GetComponents<CanvasGroup>();
if (cg != null){
foreach (CanvasGroup cgs in cg) {
cgs.alpha = alphavalue;
}
}
}
}
// Find a child transform by name
public static Transform FindTransform(Transform parent, string name)
{
if (parent.name.Equals(name)) return parent;
foreach (Transform child in parent)
{
Transform result = FindTransform(child, name);
if (result != null) return result;
}
return null;
}
}
















